Sadržaj
Detekcija malicioznih PDF datoteka metodama strojnog učenja
Sažetak
Kompleksnost i struktura modernih digitalnih dokumenata omogućuje skrivanje ili namjerno predstavljanje malicioznog koda kao skupa korisnih podataka. Iz tog razloga se takozvani trojanski dokumenti često koriste kao sredstvo za distribuciju malicioznog koda, često djelujući kao legitimni i korisni dokumenti. Cilj takvih napada je iskoristiti ranjivosti u klijentskoj aplikaciji kako bi se postiglo izvršavanje proizvoljnog programskog koda. PDF dokumenti, jedni od najraširenije korištenih dokumenata, su postali popularni zahvaljujući svojoj jednostavnosti i širokom spektru funkcionalnosti koje nude. Ovaj seminar obradit će metodu statičke analize PDF dokumenata koja uz pomoć algoritama strojnog učenja obavlja klasifikaciju PDF dokumenta na benigni ili maliciozni dokument. Osim klasifikacije benignog/malicioznog dokumenta, ista metoda će se iskoristiti za klasifikaciju malicioznih dokumenata na one koji su namijenjeni za phishing napade na velikoj skali i onih koji su namijenjeni za ciljane napade.
Uvod
Trojanski dokumenti iskorištavaju ranjivosti sve većeg broja aplikacija za pregledavanje dokumenata, često u kombinaciji s društvenim inženjeringom kako bi zavarali žrtve o legitimnosti tih dokumenata. Na primjer, skrivanje malicioznog koda u lažne izvode iz banke, izvješća tvrtki itd. Općenito postoje dvije vrste napada. Prvi su phishing napadi izvedeni na velikoj skali čiji je cilj špijunaža i prikupljanje podataka o velikom broju slučajnih žrtava. Drugi tip su ciljani napadi koji koriste znanje o određenoj osobi ili entitetu.
PDF dokumenti jedan su od najpopularnijih formata datoteka za izvođenje ovih vrsta napada. Napadači koriste mnogo različitih metoda i strategija za izvođenje tih napada koristeći PDF datotečni format. Neki od tih metoda su:
- korištenje dokumenta isključivo radi iskorištavanja ranjivosti u klijentskoj aplikaciji za čitanje dokumenata
- korištenje dokumenta za prijenos kompletnog malicioznog koda na računalo žrtve
- korištenje dokumenta koji ima ugrađen kod za preuzimanje malicioznog koda s interneta
Za otkrivanje malicioznih PDF dokumenata obično postoje dva pristupa. Prvi pristup je statička analiza dokumenta koja koristi signature analysis ili regularne izraze kako bi se ekstrahirali uzorci i usporedili s bazom uzoraka malicioznih kodova. Drugi pristup je dinamička analiza koja analizira ponašanje dekodiranog PDF dokumenta.
Metoda opisana u ovom seminaru bazirana je statičkoj analizi. Korištenjem regularnih izraza, za svaki dokument u skupu podataka izvlače se značajke iz metapodataka dokumenta te njegovih strukturnih elemenata, bez potrebe za dekodiranjem samog PDF dokumenta. Te se značajke zatim predaju algoritmu strojnog učenja zvanim Random forests, čiji je cilj naučiti uzorke koji se nalaze u podacima te iskoristiti te uzorke za razlikovanje benignih od malicioznih dokumenata.
Temeljna je pretpostavka da će svaka dva benigna dokumenta imati slične ekstrahirane značajke. Ista pretpostavka vrijedi i za dva maliciozna dokumenta. No, dva dokumenta neće imati slične značajke ako je jedan od njih benigni, a drugi maliciozan.
Glavna prednost pristupa koji koristi algoritme strojnog učenja je mogućnost generaliziranja na nove vrste malicioznog koda. Metoda je agnostična na specifične ranjivosti te ne zahtijeva prethodno znanje o obiteljima malicioznog koda.
Ekstrakcija i selekcija značajki
Koriste se dva različita skupa podataka, jedan za fazu treniranja i drugi za fazu testiranja. Detaljnije informacije o skupovima podataka i načinu njihova prikupljanja mogu se naći u originalnom članku ove metode [1].
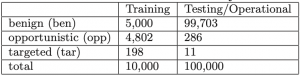
Nad svakim dokumentom provodimo ekstrakciju značajki iz metapodataka i strukturalnih elemenata korištenjem regularnih izraza, njih ukupno 202 po dokumentu. Neke od tih značajki su:
- Broj font objekata (“/Font” markeri)
- Prosječna duljina stream objekata (razlika između pozicija “/Stream” i “/Endstream” markera)
- Broj JavaScript objekata (“/JavaScript” markeri)
- Broj JS objekata (“/JS” markeri)
- Dimenzije box i image objekata
- Broj malih slova u naslovu
- Suma piksela u svim slikama
- …
Ova metoda ekstrakcije značajki također dobro radi i na enkriptiranim dokumentima jer kod takvih dokumenata metapodaci i strukturalni elementi ostaju dekriptirani. Gotovo sve značajke su numeričke, a one koje nisu se transformiraju tako da postanu numeričke.
Sve značajke su odabrane na način da se neutralizira ovisnost o nizovima znakova i bajtova specifičnim za neki napad ili familiju malicioznog koda, s razlogom da se poveća generalizacija algoritma strojnog učenja. Također, izbjegavaju se značajke poput imena autora ili broj znakova u polju imena autora.
Klasifikacija korištenjem algoritma Random forests
Random forests algoritam je zapravo ansambl velikog broja stabala odlučivanja koji su trenirani na slučajnim podskupovima skupa značajki. Rezultat se dobiva metodom glasanja stabala odluke. Više o Random forests algoritmu može se pronaći u [2].
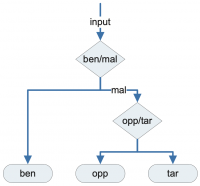
Ova metoda uključuje treniranje dva različita Random forests klasifikatora. Prvi klasifikator odlučuje o tome je li PDF dokument benigni ili maliciozan. Drugi klasifikator primjenjuje se samo na maliciozne PDF dokumente. Njegova uloga je klasifikacija dokumenta na one koji su namijenjeni phishing napadima na velikoj skali ili na one koji su namijenjeni za ciljane napade. Na donjoj slici ilustriran je ovaj pristup. Benigni dokumenti su označeni sa “ben”, a maliciozni sa “mal”. Maliciozni dokumenti namijenjeni phishing napadima na velikoj skali označeni su sa “opp”, a oni za ciljane napade su označeni sa “tar”.
Kako bi se postigli najbolji rezultati s Random forests algoritmom, autori metode pretražuju prostor hiperparametara koji maksimiziraju točnost na testnom skupu dokumenata. Vremensko trajanje procesa treniranja kao i obično ovisi o veličini skupa podataka s kojim algoritam strojnog učenja raspolaže. U članku koji predstavlja ovu metodu treniranje je trajalo 15 minuta.
Važno je da mehanizam za detekciju bilo koje vrste malicioznih datoteka, pa tako i PDF datoteka, bude otporan na metode izbjegavanja otkrivanja (eng. detection evasion). Napadači uz poznavanje algoritma detekcije mogu pokušati zavarati sustav namjernim prilagođavanjem dokumenta kako bi proizveli dokument koji izgleda benigno. Zato je važno da sustav za detekciju bude robustan i otporan na takve napade. Takve vrste napada na sustave bazirane na algoritmima strojnog učenja nazivamo napadi neprijateljskim primjerima (eng. adversarial attack). Cilj im je izgraditi primjer dokumenta koji će prevariti klasifikator.
Ova metoda pokazuje visok stupanj otpornosti na napade neprijateljskim primjerima. Međutim, autori ove metode pokazuju da je robusnost moguće povećati perturbacijom skupa značajki za učenje algoritma. U suštini cilj je unijeti neku razinu šuma u podatke, što će imati efekt porasta varijabilnosti u podacima. Algoritmu strojnog učenja bit će otežano favoriziranje određenih značajki u odnosu na druge.
Rezultati i analiza
Svaki od klasifikatora je evaluiran na testnom skupu dokumenata. Rezultati su prikazani u sljedećim tablicama, koristeći standardne klasifikacijske metrike [5].
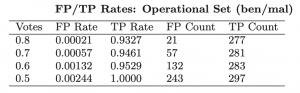
Donja tablica prikazuje performanse prvog klasifikatora benignih i malicioznih PDF dokumenata. Vidljivo je da je postotak detekcije malicioznih primjera vrlo visok (TP rate u tablici), dok je razina false positive slučajeva vrlo niska (FP rate u tablici).
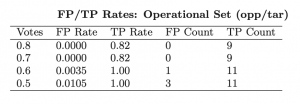
Donja tablica prikazuje performanse drugog klasifikatora za klasifikaciju PDF dokumenata namijenjenih za phishing napade na velikoj skali i one namijenjene za ciljane napade. Postotak detekcije malicioznih dokumenata za ciljane napade je također vrlo visok (TP rate u tablici), dok je razina false positive slučajeva opet vrlo niska (FP rate u tablici).
Jednom kad je treniranje klasifikatora gotovo moguće je upakirati klasifikatore u desktop program ili ih koristiti kao servis preko Interneta. Izvođenje klasifikatora na novom dokumentu za koji nas zanima klasifikacija traje 1 sekundu.
Zaključak
Ovaj seminar istražuje pristup otkrivanja malicioznih PDF dokumenata koristeći algoritme strojnog učenja. Značajke se ekstrahiraju statičkom analizom, konkretno regularnim izrazima, iz metapodataka i strukturnih elemenata. Rezultat ovog pristupa su dva klasifikatora. Prvi klasifikator koristi se za početno otkrivanje malicioznih PDF dokumenata. Jednom kada je otkriven maliciozni PDF dokument, drugi klasifikator predviđa vrstu napada koju dokument provodi, phishing napad na velikoj skali ili ciljani napad. Ovom se metodom postiže visoka točnost te robusnost na metode izbjegavanja detekcije.
